Windows Server Data Deduplication 檔案層級重複資料刪除
前言

Windows Server 從 2012開始支援檔案層級重複資料刪除,Windows 2012當年僅支援單線程處理所以其實不好用,Windows Server 2016之後開始支援多線程處理,Windows Server 2019開始支援ReFS的重複資料刪除,且現今大部分主流備份系統都支援Dedupe Volume的備份還原,讓整個Solution好用很多,但鍵人發現此功能仍鮮少人知故特別在此分享推廣一下。
系統需求

OS: Windows Server 2012 以上,但建議在Windows Server 2016 以上使用
CPU: 至少4 Core,但多一點比較好
Memory: 系統最少保留 4GB+ 且每 1TB 需要 1GB RAM,如果需要Dedupe的Volume 10TB,記憶體需要 14GB (4GB+10GB)
最小可Dedupe檔案大小: 預設32KB,但可以透過Powershell變更檔案大小
磁碟格式: NTFS / ReFS (2019+)
磁碟大小支援: Windows 2016後可支援最大 64TB的空間進行Dedupe,根據不同的 Cluster Size 可支援的大小不同,Windows預設Cluster Size為4KB下最大空間僅支援16TB。


適用情境: File Server、HyperV、HyperV Cluster、Backup Storage
HyperV 高IO Production 環境下不建議使用
預期Dedupe效率: 根據Microsoft官方說法如下

運作原理
1. 掃描檔案系統以尋找符合最佳化原則的檔案。

2. 將檔案分成可變更大小的區塊。

3. 識別唯一的區塊。

4. 將區塊放入區塊存放區,並選擇性壓縮。
5. 使用重新分析點將區塊存放區中的原始檔案資料流取代為現在已最佳化的檔案。

詳細請參照 https://learn.microsoft.com/zh-tw/windows-server/storage/data-deduplication/overview
安裝設定過程
安裝步驟
1. 伺服器管理員 => 管理 => 新增角色及功能 。

2. 展開 檔案和存放服務,點選 重複資料刪除。




3. 新增所需要的功能並安裝。



4. 安裝完成 全文完 ...... 沒有開玩笑的啦 .o(≧∀≦)o

5. 在Service中會出現兩個Dedupe的服務

評估Dedupe效益
Windows有提供預先評估工具來評估Dedupe是否有效益,如果效益不佳就不要使用將服務移除就好
首先我先將Windows Server 2022 ISO Copy 至 D:\,並且再複製一份

先看一下2022 ISO檔大小5.29GB

磁碟大小 10.7GB

執行Dedupe評估工具DDPEVAL.EXE
ddpeval "D:" /V
由上面結果看來可Dedupe 57%,再來複製第三份 2022 ISO

再跑一次評估工具,預估可以Dedupe 78%

設定Dedupe
至 伺服器管理員 => 檔案和存放服務

選取 磁碟 => 設定重複資料刪除

依據你的用途選擇對應的Dedupe政策

預設的政策內容差異請參照
https://learn.microsoft.com/zh-tw/windows-server/storage/data-deduplication/understand

在這邊我們選擇檔案伺服器,順便看一下預設的最佳化排程

有啟用背景最佳化,這樣已足夠,確認後離開

Dedupe常用指令
先來介紹一下一些Dedupe常用的指令,後面會用到,參考資料
https://learn.microsoft.com/en-us/powershell/module/deduplication/
Get-DedupVolume
Get-DedupStatus
Get-DedupSchedule
Get-DedupJob執行Dedupe最佳化
預設狀況,背景最佳化會每天自動進行數次,我們可以透過 Get-DedupSchedule 來看最佳化的排程

或者可以到工作排程器來查看執行狀況

這裡我們可以利用Powershell手動進行最佳化,參考資料
Start-DedupJob -Volume "D:" -Type Optimization -Memory 50
透過 Get-DedupJob 指令來觀察任務執行狀況

同時也可以透過資源監視器,看到Dedupe進行的狀態

靜待 Get-dedupJob 沒有顯示任何Job時,最佳化完成

確認Dedupe結果
透過 Get-DedupStatus、Get-DedupVolume 來確認 Dedupe 結果
Get-DedupStatus
Get-DedupVolume
由上圖可知,總共4個檔案節省了16.8GB,Dedupe Rate 71%
可以看到磁碟已使用空間變大了

或者也可以透過 伺服器管理員 => 磁碟 => 內容 來確認 Dedupe 狀況


檔案顯示差異
要如何知道哪個檔案有Dedupe過,那些沒有Dedupe過 ? 從檔案的磁碟大小即可分辨
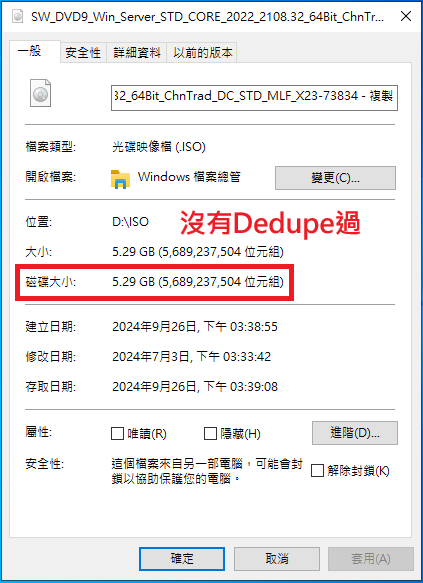
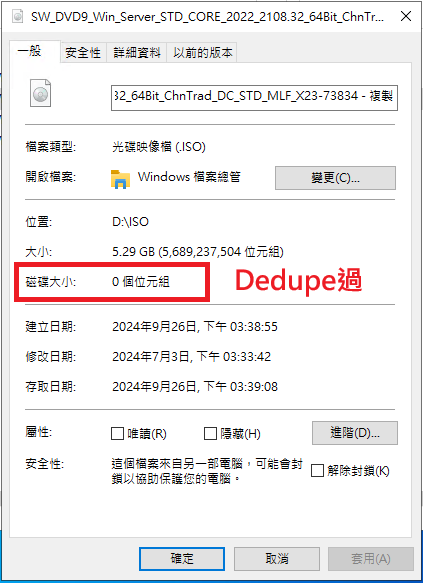
Dedupe過後,檔案的磁碟大小不見得會是0,但肯定很小
實務案例
看Lab沒啥感覺,來看看天殺の鍵人我的實際專案建置狀況
案例一:檔案伺服器
20TB 檔案伺服器,8,082,185個檔案與目錄僅占5.23TB,Dedupe Rate 72%,節省了13.75TB,如果沒有Dedupe則需要 5.23+13.75=18.98TB


案例二:HyperV Host(單台)
1.71TB HyperV Host,64個檔案與目錄僅占484GB,Dedupe Rate 73%,節省了1.34TB,如果沒有Dedupe則需要 0.48+1.34=1.82TB (根本超過本身的磁碟空間大小)



案例三:HyperV Cluster
7TB HyperV Cluster,185個檔案與目錄僅占4.16TB,Dedupe Rate 59%,節省了6.17TB,如果沒有Dedupe則需要 4.16+6.17=10.33TB (根本超過本身的磁碟空間大小)



優化校調
由於Windows Server Data Deduplication會去定期將所有檔案作Optimize最佳化運算,但由於Optimize不外乎就是大量的IO讀寫,有些時候有可能會影響Service Performance,比方說User可能會跟你說有時候會很慢,此時可以透過下面兩個方式調整優化。
排除不需要Optimize的物件
在Dedupe設定中,可以排除副檔名與目錄,以下圖為例,我將D:\temp排除不作Dedupe,以此來加速Optimize最佳化運算,以降低高IO讀寫對系統的Impact

最佳化排程調整
由於Default Optimize最佳化運算排程一天會跑個3次左右,你發現會影響Service Performance,尤其是Hyperv的環境下,User跟你說裡面的虛擬機有時候正常但有時候回應很慢,你可能會發現慢的時候Guest OS的 IO Latency很高,同時以 Get-DedupJob 確認Hyperv Host是正在進行Optimize最佳化運算導致,此時就建議自行更改Optimize最佳化運算的排程,更改Optimize最佳化運算排程方式有二。
第一種方式
透過剛剛Dedupe GUI設定,設定Dedupe排程

取消 背景最佳化,排除User會使用、備份系統運作、內部Guest OS排程,自行評估使用時段設定一個時間。

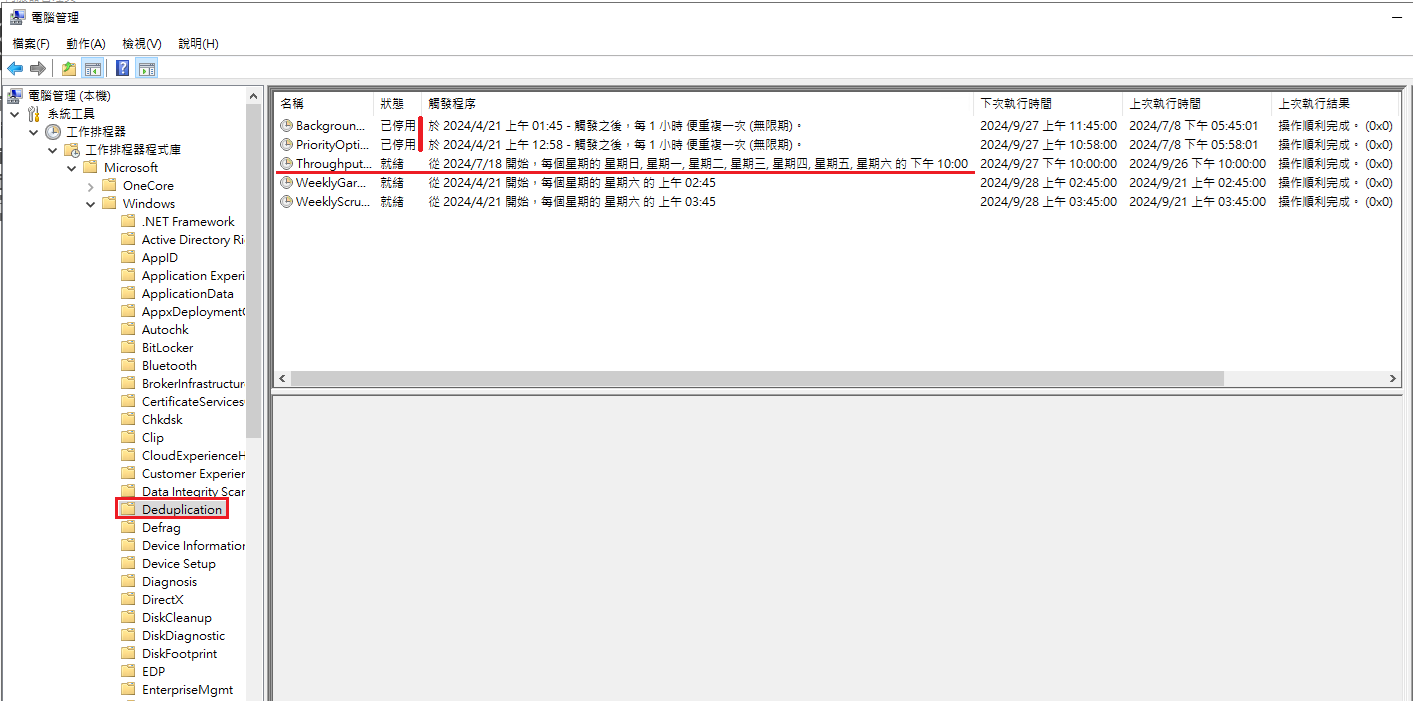
設定完成後可透過 Get-DedupSchedule 指令或工作排程器來確認排程是否正確
Get-DedupSchedule
第二種方式
透過Powershell設定,停用預設排程並設定新排程,範例如下請參照
https://learn.microsoft.com/zh-tw/windows-server/storage/data-deduplication/advanced-settings
Set-DedupSchedule -Name BackgroundOptimization -Enabled $false
Set-DedupSchedule -Name PriorityOptimization -Enabled $false
New-DedupSchedule -Name "NightlyOptimization" -Type Optimization -DurationHours 11 -Memory 50 -Cores 80 -Priority High -Days @(1,2,3,4,5) -Start (Get-Date "2016-08-08 19:00:00")
Un-Dedupe
Powershell請參照
Expand-DedupFile -Path "D:\Share\"Pros & Cons
說到這邊,相信大家都已經開始深深愛上Windows Server Data Deduplication 了,但在此還是要提一下Dedupe的優缺點。
缺點
- 系統資源需求較高,Storage越大所需要的記憶體越多。
- 讀取一般檔案時是去讀取分散的Chunk,連續讀取速度相較於沒有Dedupe時慢。
- 會需要定時進行Optimize、Garbage Collect、Scrubbing,此時磁碟的高IO可能會導致IO Latency明顯增加,進而造成服務回應變慢。
- 影像、音樂、串流 檔案無任何Dedupe效果,如果仍然想確認可執行DDPEVAL.EXE進行評估。
- 如果有長官詢問檔案有多大你可以回答這個問題,但你無法回答把這個檔案放到File Server上會額外使用多少空間,你也無法回答刪除這些檔案後能夠釋放多少空間。
- 由於Chunk的唯一性,請好好的作好Raid與Backup,一旦磁碟壞軌資料損毀你無法預期會有多大的影響。
- 使用Robocopy可能會出問題,不是不能用但請先搞清楚那些參數不能用,請參照下方。
https://learn.microsoft.com/zh-tw/windows-server/storage/data-deduplication/interop#robocopy

優點
- 大幅降低 File Server、Hyperv、Backup 所需要的磁碟空間。
- 當作File Server使用時,完全可以依照原來Windows權限設定方式設定。
- 儘管讀取一般檔案時是去讀取分散的Chunk,連續讀取速度相較於沒有Dedupe時慢,某些文獻上有提到由於Hyperv在讀取一般磁碟時會Bypass Cache,但是由於Chunk可以透過記憶體快取,所以做了 Data Deduplication 反而有助於改善Hyperv BootStorm(開機風暴)問題。
參考資料:https://aidanfinn.com/?p=14863

結語
Windows Server Data Deduplication 此功能有著大幅降低所需要的磁碟空間顯著的優點,但同時也有一些不能忽視的缺點,審慎妥善的評估情境是否適用、作好萬全的防護措施,Windows Server Data Deduplication 絕對能帶給你前所未有的絕妙體驗。
參考資料
https://learn.microsoft.com/zh-tw/windows-server/storage/data-deduplication/overview
https://learn.microsoft.com/zh-tw/windows-server/storage/data-deduplication/understand
https://learn.microsoft.com/zh-tw/windows-server/storage/data-deduplication/install-enable
https://learn.microsoft.com/zh-tw/windows-server/storage/data-deduplication/interop
https://learn.microsoft.com/en-us/powershell/module/deduplication/
https://learn.microsoft.com/en-us/windows-server/storage/file-server/ntfs-overview